728x90
반응형
SMALL
리스트란?
▶ 리스트의 개념
- 리스트(List) : 하나의 변수에 여러 값을 할당하는 자료형
- 여러 데이터를 순서대로 하나의 변수에 할당하는 시퀀스형 자료형
- 시퀀스형 : 무언가의 조합으로 이루어진 자료형 - 하나의 자료형만 저장하지 않고, 정수형이나 실수형 같은 다양한 자료형을 포함할 수 있음
- 리스트는 [대괄호] 로 작성하며, 내부 원소는 , 로 구분
### 리스트 ###
colors=['red', 'green', 'blue']
print(colors)
# 실행결과
['red', 'green', 'blue']▶ 인덱싱과 슬라이싱 : 인덱싱(indexing)
- 인덱싱 : 리스트에 있는 값에 접근하기 위해, 이 값의 상대적인 주소를 사용하는 것
### 인덱싱 ###
colors=['red', 'green', 'blue'] # 인덱스 0 1 2
print(colors[0])
print(colors[1])
print(len(colors)) #colors의 길이
colors[2]='pink' @ blue -> pink로 변경(인덱스의 재할당 : 인덱스에 새로운 값을 할당)
print(colors)
# 실행결과
red
green
3
['red', 'green', 'pink']▶ 인덱싱과 슬라이싱 : 슬라이싱(slicing)
- 슬라이싱 : 리스트의 인덱스를 사용하여 전체 리스트에서 일부를 잘라내어 반환
- 변수명[시작 인덱스:마지막인덱스]
- 파이썬의 리스트에서 '마지막 인덱스-1'까지만 출력됨
- 만약 한 번 이상 리스트 변수를 사용하면 마지막 인덱스가 다음 리스트의 시작 인덱스가 되어 코드를 작성할 때 조금 더 쉽게 이해 할 수 있다는 장점이 있음
cities=['서울','부산','인천','대구','대전','광주','울산','수원']
print(cities)
print(type(cities))
print(len(cities))
# 실행결과
['서울', '부산', '인천', '대구', '대전', '광주', '울산', '수원']
<class 'list'>
8
### 슬라이싱(slicing) ###
print(cities[1:4])
print(cities[0:4])
print(cities[:4])
print(cities[3:8])
print(cities[3:])
print(cities[0:8])
print(cities[:]) # cities 변수의 처음부터 끝까지
# 실행결과
['부산', '인천', '대구']
['서울', '부산', '인천', '대구']
['서울', '부산', '인천', '대구']
['대구', '대전', '광주', '울산', '수원']
['대구', '대전', '광주', '울산', '수원']
['서울', '부산', '인천', '대구', '대전', '광주', '울산', '수원']
['서울', '부산', '인천', '대구', '대전', '광주', '울산', '수원']▶ 인덱싱과 슬라이싱 : 리버스 인덱스(reverse index)
- 리스트에는 인덱스를 마지막 값부터 시작하는 리버스 인덱스 기능이 있음

### 리버스 인덱스 ###
print(cities[-8:-3])
print(cities[-8:])
# 일반적으로 시작 인덱스가 비어있으면 처음부터, 마지막 인덱스가 비어 있으면 마지막까지라는 의미로 사용됨
# 즉, cities[-8:]은 인덱스가 -8인 '서울'부터 '수원'까지 출력하라는 뜻
print(cities[:-2])
# 실행결과
['서울', '부산', '인천', '대구', '대전']
['서울', '부산', '인천', '대구', '대전', '광주', '울산', '수원']
['서울', '부산', '인천', '대구', '대전', '광주']▶ 인덱싱과 슬라이싱 : 인덱스 범위를 넘어가는 슬라이싱
- 인덱스를 따로 넣지 않고print(cities[:])과 같이 콜론(:)을 넣으면 cities 변수의 모든 값을 다 반환
- 슬라이싱에서는 인덱스를 넘어서거나 입력하지 않더라도 자동으로 시작 인덱스와 마지막 인덱스로 지정됨
cities=['서울','부산','인천','대구','대전','광주','울산','수원']
print(cities[:]) # cities 변수의 처음부터 끝까지
print(cities[-50:50]) # 범위를 넘어갈 경우 자동으로 최대 범위를 지정
# 실행결과
['서울','부산','인천','대구','대전','광주','울산','수원']
['서울','부산','인천','대구','대전','광주','울산','수원']▶ 인덱싱과 슬라이싱 : 증가값(step)
- 슬라이싱에서는 시작 인덱스와 마지막 인덱스 외에 마지막 자리에 증가값을 넣을 수 있음
- 증가값은 한 번에 건너뛰는 값의 개수
- 변수명[시작 인덱스:마지막 인덱스:증가값]
cities=['서울','부산','인천','대구','대전','광주','울산','수원']
print(cities[::2]) # 2칸 단위로
print(cities[::-1]) # 역으로 슬라이싱
# 실행결과
['서울', '인천', '대전', '울산']
['수원', '울산', '광주', '대전', '대구', '인천', '부산', '서울']
### 문자 역순 출력 ###
s="abcdefg"
print(s[::-1])
# 실행결과
gfedcba
▶ 리스트의 연산
- 덧셈 연산 : 덧셈 연산을 하더라도 따로 어딘가 변수에 할당해 주지 않으면 기존 변수는 변화가 없음
- 곱셈 연산 : 리스트의 곱셈 연산은 기준 리스트에 n을 곱했을 경우, 같은 리스트를 n배만큼 늘려줌
- in 연산 : 포함 여부를 확인하는 연산, 하나의 값이 해당 리스트에 들어 있는지 확인 할 수 있음
### 리스트 연산 ###
colors1=['red', 'green', 'blue', 'orange']
colors2=['orange', 'black', 'white']
print(colors1+colors2) # 두 리스트 합치기
total_color = colors1+colors2
print(total_color)
print(colors1*2) # colors1 리스트 2회 반복
print('blue' in colors1) # colors1 변수에 문자열 'blue'의 존재 여부 반환
print('blue' in colors2) # colors2 변수에 문자열 'blue'의 존재 여부 반환
# 실행결과
['red', 'green', 'blue', 'orange', 'orange', 'black', 'white']
['red', 'green', 'blue', 'orange', 'orange', 'black', 'white']
['red', 'green', 'blue', 'orange', 'red', 'green', 'blue', 'orange']
True
False▶ 리스트 추가 및 삭제
append() 함수 : 새로운 값을 기존 리스트의 맨 끝에 추가
### append() 함수 ###
colors1.append('white')
print(colors1)
# 실행결과
['red', 'green', 'blue', 'orange', 'white']
number=[]
number.append(1)
print(number)
number.append(10)
print(number)
# 실행결과
[1]
[1, 10]
extend() 함수 : 새로운 리스트를 기존 리스트에 추가
### extend() 함수 ###
number2=[100,200,300]
number.extend(number2)
print(number)
# 실행결과
[1, 10, 100, 200, 300]
insert() 함수 : 기존 리스트의 i번째 인덱스에 새로운 값을 추가, i번째 인덱스를 기준으로 뒤쪽의 인덱스가 하나씩 밀림
### insert() 함수 ###
number.append(1000) # 새로운 값을 기존 리스트의 맨 끝에 추가
print(number)
number.insert(1, 500) # 1번째 인덱스에 500으로 추가
print(number)
# 실행결과
[1, 10, 100, 200, 300, 1000]
[1, 500, 10, 100, 200, 300, 1000]
remove() 함수 : 리스트 내의 특정 값을 삭제
### remove() 함수 ###
number.remove(1) # 1이라는 값 삭제
print(number)
# 실행결과
[500, 10, 100, 200, 300, 1000]
del() 함수 : 특정 인덱스값을 삭제
### del() 함수 ###
del number[0]
print(number)
# 실행결과
[10, 100, 200, 300, 1000]
▶ 패킹과 언패킹
- 패킹(packing) : 한 변수에 여러 개의 데이터를 할당하는 것
- 언패킹(unpacking) : 한 변수에 데이터를 각각의 변수로 반환하는 것
### 패킹, 언패킹 ###
t=[1,2,3] # 1,2,3을 변수t에 패킹
a,b,c=t # t에 있는 값 1,2,3을 변수 a,b,c에 언패킹
print(t, a,b,c)
# 실행결과
[1, 2, 3] 1 2 3
리스트에 값이 3개인 경우, 5개로 언패킹을 시도한다면 어떤 결과가 나올까?
- 언패킹 시 할당받는 변수의 개수가 적거나 많으면 모두 에러가 발생함!!

▶ 이차원 리스트
- 리스트를 효율적으로 활용하기 위해 여러 개의 리스트를 하나의 변수에 할당하는 이차원 리스트를 사용할 수 있음
- 이차원 리스트는 표의 칸에 값을 채웠을 경우 생기는 값들의 집합임

- 이차원 리스트를 하나의 변수로 표현하기 위해서 다음과 같이 코드를 작성
- 이차원 리스트에 인덱싱하여 값에 접근하기 위해서는 대괄호 2개를 사용
### 이차원 리스트 ###
kor=[40,50,85,95]
math=[50,60,80,90]
eng=[60,65,75,85]
score=[kor, math, eng]
print(score)
print(score[1])
print(score[2][2])
math[0]=55
print(score)
kor[3]=80
print(score)
# 실행결괴
[[40, 50, 85, 95], [50, 60, 80, 90], [60, 65, 75, 85]]
[50, 60, 80, 90]
75
[[40, 50, 85, 95], [55, 60, 80, 90], [60, 65, 75, 85]]
[[40, 50, 85, 80], [55, 60, 80, 90], [60, 65, 75, 85]]▶ 리스트의 메모리 저장
- 파이썬은 리스트를 저장할 때 값 자체가 아니라, 값이 위치한 메모리 주소(reference)를 저장
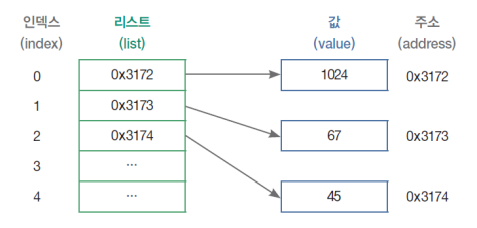
- == : 값을 비교하는 연산, is : 메모리의 주소를 비교하는 연산
a=300
b=300
# 값을 비교하는 연산자
print(a==b)
# 메모리의 주소를 비교하는 연산
# -5부터 256까지의 정수 값을 특정 메모리 주소에 저장하기때문에 300은 False로 나옴
print(a is b)
a=5
b=5 #b=a 메모리 값 같은 위치
print(a==b)
print(a is b) #a와b가 같은 메모리인가
# 실행결과
True
False
True
True
- 리스트는 기본적으로 값을 연속으로 저장하는 것이 아니라, 값이 있는 주소를 저장하는 방식

▶ 메모리 저장 구조로 인한 리스트의 특징
- 다양한 형태의 변수가 하나의 리스트에 들어갈 수 있음
- 기존 변수들과 함께 리스트 안에 다른 리스트를 넣을 수 있음. 흔히 이를 중첩 리스트라고 함. 이러한 특징은 파이썬의 리스트가 값이 아닌 메모리의 주소를 저장해 메모리에 새로운 값을 할당하는 데 있어 매우 높은 자유도를 보장하므로 가능함

리스트의 저장 방식
- b와 a 변수를 각각 다른 값으로 선언한 후, b에 a를 할당. 왼쪽 그림과 같이 b를 출력하면, a 변수와 같은 값이 화면에 출력됨
- 오른쪽 그림과 같이 a만 정렬하고 b를 출력했을 때 b도 정렬됨

- sort() 함수 : 정렬

- b에 새로운 값을 할당하면 b는 이제 새로운 메모리 주소에 새로운 값을 할당할 수 있을 것

### 리스트의 저장 방식 ###
a=[50,40,30,20,10]
b=[1,2,3,4,5]
print(a,b)
# 실행결과
[50, 40, 30, 20, 10] [1, 2, 3, 4, 5]
b=a
print(a,b)
# 실행결과
[50, 40, 30, 20, 10] [50, 40, 30, 20, 10]
### sort() 함수 : 정렬 ###
a.sort()
print(b)
# 실행결과
[10, 20, 30, 40, 50]728x90
반응형
LIST
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 반복문(for, while) (0) | 2021.12.06 |
|---|---|
| [Python] 조건문(conditional statement) (0) | 2021.12.06 |
| [Python] 변수와 자료형 (0) | 2021.12.05 |
| [Python] 아나콘다/ 주피터 노트북(Anaconda/jupyter notebook) 설치하기 on windows (0) | 2021.12.04 |




댓글